Existing research on video understanding in natural language question answering often employs an offline feature extraction approach for inference. However, this approach has several drawbacks: 1) Video or text feature extractors are usually trained on different tasks, resulting in disparities with the target task. For instance, utilizing feature extractors trained on action recognition datasets directly for video question answering tasks is suboptimal. 2) Individual feature extractors are usually trained separately on their respective domain datasets, resulting in a lack of cohesion between the modal features. 3) To enhance question answering inference performance, such methods often rely on complex feature extractors or text analysis tools to effectively process videos or questions. Therefore, adopting an end-to-end approach to simultaneously learn natural language questions and video content is an effective solution to address these shortcomings. Despite recent end-to-end methods achieving excellent recognition performance in question answering inference by simultaneously learning feature extraction and multimodal information interaction, these methods primarily focus on building large-parameter models and exploring how to utilize pre-training on large-scale visual-text corpora to enhance task performance, which often requires substantial computational resources and entails high human costs in data annotation and model training.
In response to the aforementioned issues with existing research methods, our research team proposes an efficient end-to-end video and language joint learning approach. This method combines validated local spatial information and temporal dynamic characteristics from existing research to enhance question answering inference accuracy. By designing a pyramid-style video and language interaction structure, the method decomposes the video into spatial and temporal features of different granularities and stacks multiple multimodal Transformer layers to extract interactions between them and questions, facilitating the extraction of local and global dependencies between video and text. Additionally, to more fully exploit the local and global interactive features at each layer, the method designs a context-matching lateral connection operation and multi-step loss constraints to gradually extract locally and globally semantic complete interactive features.
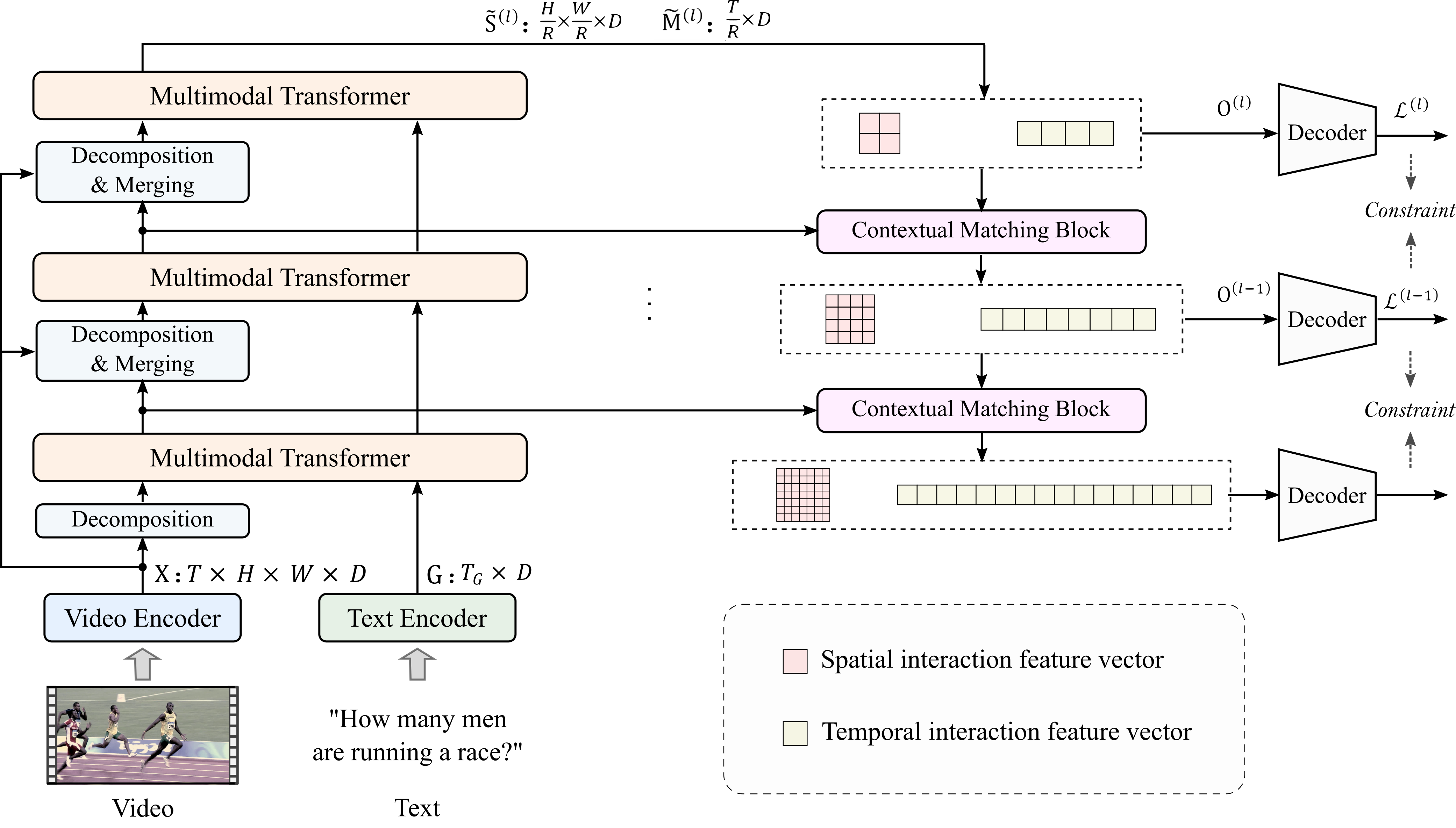
The framework of our method
This research method achieves better or comparable inference performance compared to existing methods without the need for large-parameter feature extraction and interaction models and without relying on pre-training with large-scale visual-text data. It also demonstrates significant advantages in terms of model parameter quantity and computational efficiency. These findings are published in the AAAI Conference on Artificial Intelligence (CCF A) and are supported by the National Natural Science Foundation of China.
The link to this paper is: https://ojs.aaai.org/index.php/AAAI/article/view/25296.
