
Aiming at the problems that many existing multi-view 3D human pose estimation methods ignoring the multi-dimensional implicit information of joints, relying on scene-specific camera parameters, and insufficient mining of semantic features, our research team investigates multi-view 3D human pose estimation methods based on deep semantic graph encoders and progressive spatial-temporal fusion. This study first extracts semantic graph embedded features to describe the rich spatial structure information of human joints, then constructs multiple spatial semantic graph encoders and cross-view spatial-temporal feature fusion modules to dynamically interact and fuse different features across viewpoints. It can fully explore the deep semantic knowledge implied by joints in different viewpoints, and enhance the representativeness of the pose features.
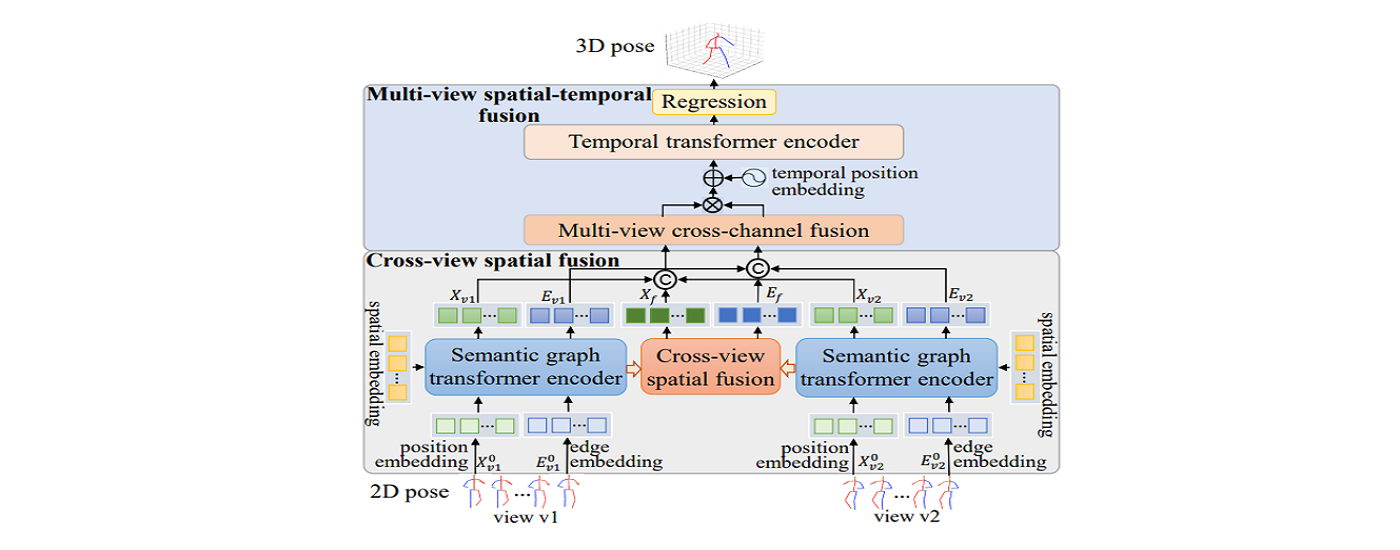
The framework of our method
This research effectively mitigates the depth ambiguity problem in single-view 3D human pose estimation and improves model performance without relying on camera extrinsic parameters. The related achievements have been published in AAAI Conference on Artificial Intelligence (CCF A) and ACM International Conference on Multimedia (CCF A).
The above work is supported by the National Natural Science Foundation of China.
Links to related papers:
https://ojs.aaai.org/index.php/AAAI/article/view/28549
https://dl.acm.org/doi/abs/10.1145/3581783.3612098